A Quick Guide to Data-Driven Testing

Modern software testing is built around the execution of test cases. A test case specifies a combination of inputs and conditions to be executed and fulfilled in the system under test. Testing then becomes a process in which testers configure the system to each test case’s specifications and verify that the system behaves as expected. There is a wide range of methods to design and create test cases; many software testers opt to manually select and write cases.
As a system grows more complex, with more features, functionalities, and system paths to verify through testing, the number of necessary test cases also increases. This can make manual test case creation methods unfeasible for a number of different reasons:

The solution? Data-driven testing.
Data-driven testing is the practice of keeping the test execution script separate from the test data being executed. As a result, data driven testing suites look different from normal sets of test cases. There is generally a single test outline, which gives generic testing instructions using placeholders that will later be filled in with specific test data.

The test data is contained in a spreadsheet, like so.
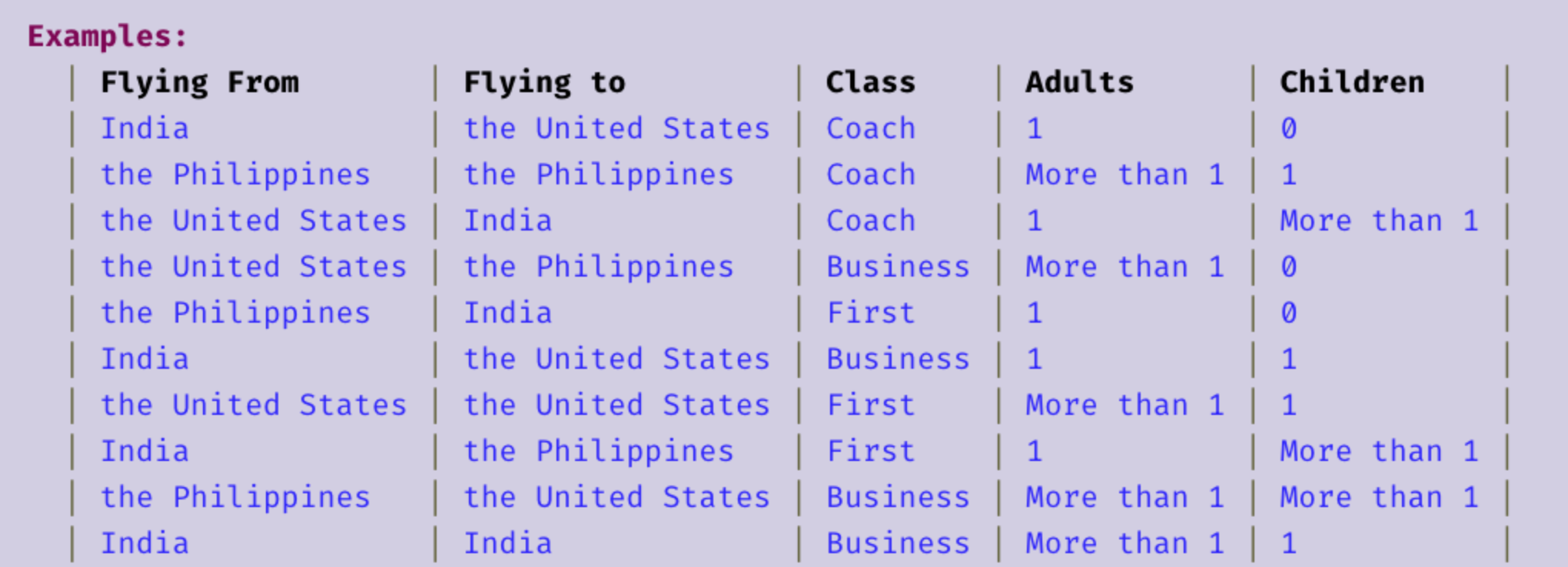
In general, the main benefits of data-driven testing are its modular nature, which allows for robust scalability, as well as its usage by a wide variety of test design tools such as Hexawise. These two characteristics of data-driven testing offer effective solutions to the main problems with manual test design outlined previously:

However, the benefits outlined in the chart above only apply when data-driven testing is implemented and utilized effectively. Factors which can make or break the effectiveness of your data-driven testing, from the design of the initial generic test and the divison of the system into the variables which make up the test data, require critical thinking and a clear understanding of the system under test. Check back next week for a introductory discussion about the best practices and common pitfalls of data-driven testing.

