How bad are normal, business-as-usual software tests?
I run into the same problem quite often: people have a hard time distinguishing between good and bad tests.
So what are ‘bad tests’?
Bad tests are those that don’t make the tester learn as much as possible with each test step. Said another way: bad tests are repetitive.
Repetitive tests are time wasters. They make testing a mundane task to be completed. Repetitive tests don’t emphasize the complexity inherent in most systems today. And they let things (read: bugs, defects, faults) slip through into production.
Experiment Time!
Question: How bad are bad tests?
Research: (not much out there)
Hypothesis: Bad tests are deceptively bad.
Experiment:
- Choose some tests.
- Model their ideas in Hexawise.
- Lock-in bad tests as Requirements.
- Find out how many of the interactions bad tests cover.
- Then see how many tests are needed to cover all pairwise interactions.
Step 1: Choosing Tests
I took some tests that some testers all agreed cover the functionality that needed to be covered for the story they were testing.
Step 2: Test Designing
I sat down and analyzed them. Repetitive as any I’d seen. I sifted through them to pull out the main testing ideas. These I would use as parameters and values. I entered these into Hexawise.
Step 3: Lock-in Bad Tests
I used our Requirements feature to lock-in their repetitive tests. So Hexawise would be forced to use their tests first (this would allow me to model how many interactions each of their tests covered)
Step 4: Analyzing Bad Tests
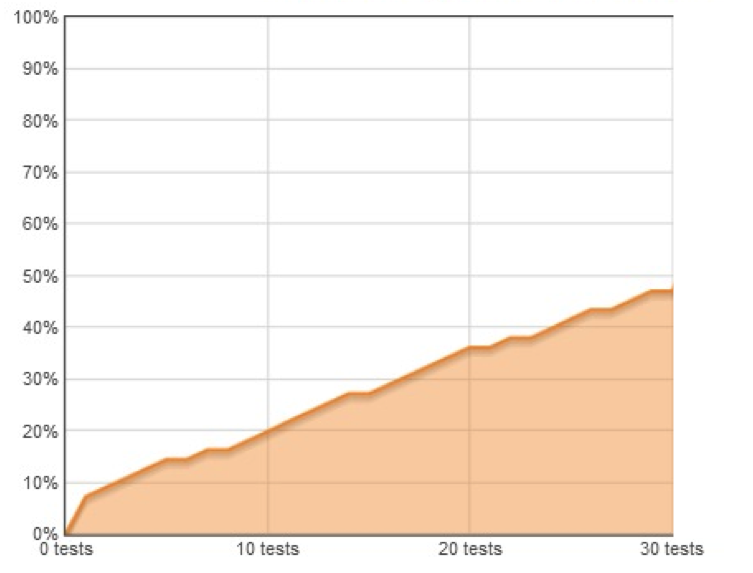
This is the chart Hexawise produced. In 30 tests, they covered 47% of the total possible pairwise interactions.

Before we go on: Do you notice that there are little plateaus? From Test 5 to 6, 7 to 8, 14 to 15, 20 to 21, 22 to 23, 26 to 27, and 29 to 30? That means those were tests that did not include ANY new pairs. No new information could have been learned from those tests. Learning literally plateaued. 7 times. Nearly 1 out of 4 tests didn't teach the testers anything.
Then I unleashed the Kraken Hexawise.
Step 5: Let Hexawise Optimize
I removed those Requirements. See how many tests Hexawise needs to cover all of the interactions in this specific functionality.

Okay, to be honest, I wanted Hexawise to do it in like 20 tests. (More Coverage. Fewer Tests.) But it used 30 (More Coverage). BUT (and this is a big BUT snickers) Hexawise covered 100% of the pairwise interactions in 30 tests.
Lessons Learned
No one would have guessed their tests were that bad by just reading through them. They looked perfectly fine. They read like good test cases. But as we started to visualize their coverage, we saw that perhaps they weren't achieving all they could. And when we compared bad tests to Hexawise tests, more coverage (in the same amount of tests) is a clear winner.
In short:
- Bad tests are deceptively bad
- Sometimes you have to prove it
- Pairwise tests can alleviate bad-test-initis


