Actionable Recommendations for Effective Software Testing

The journey to efficient software testing starts with a mindset & process shift – embracing a model-based combinatorial methodology. Traditional test design approaches often lead to the following problems:
- Direct duplicate tests due to inconsistent formatting or spelling errors
- “Hidden”/Contextual duplicates (meaningful typos; same instructions written by different people with varied styles);
- Tests specifying some values, leaving others as default (when several scenarios can be tested in the same execution run).
Adopting a more scientific strategy, as showcased in multiple Hexawise case studies, helps eliminate large amounts of inefficiency - reducing the number of tests and making the test suites more easily maintainable. This approach can be applied beyond business as usual regression optimization to scenarios like new feature releases or applications going through a redesign.
The process we recommend is shown on this flow diagram:
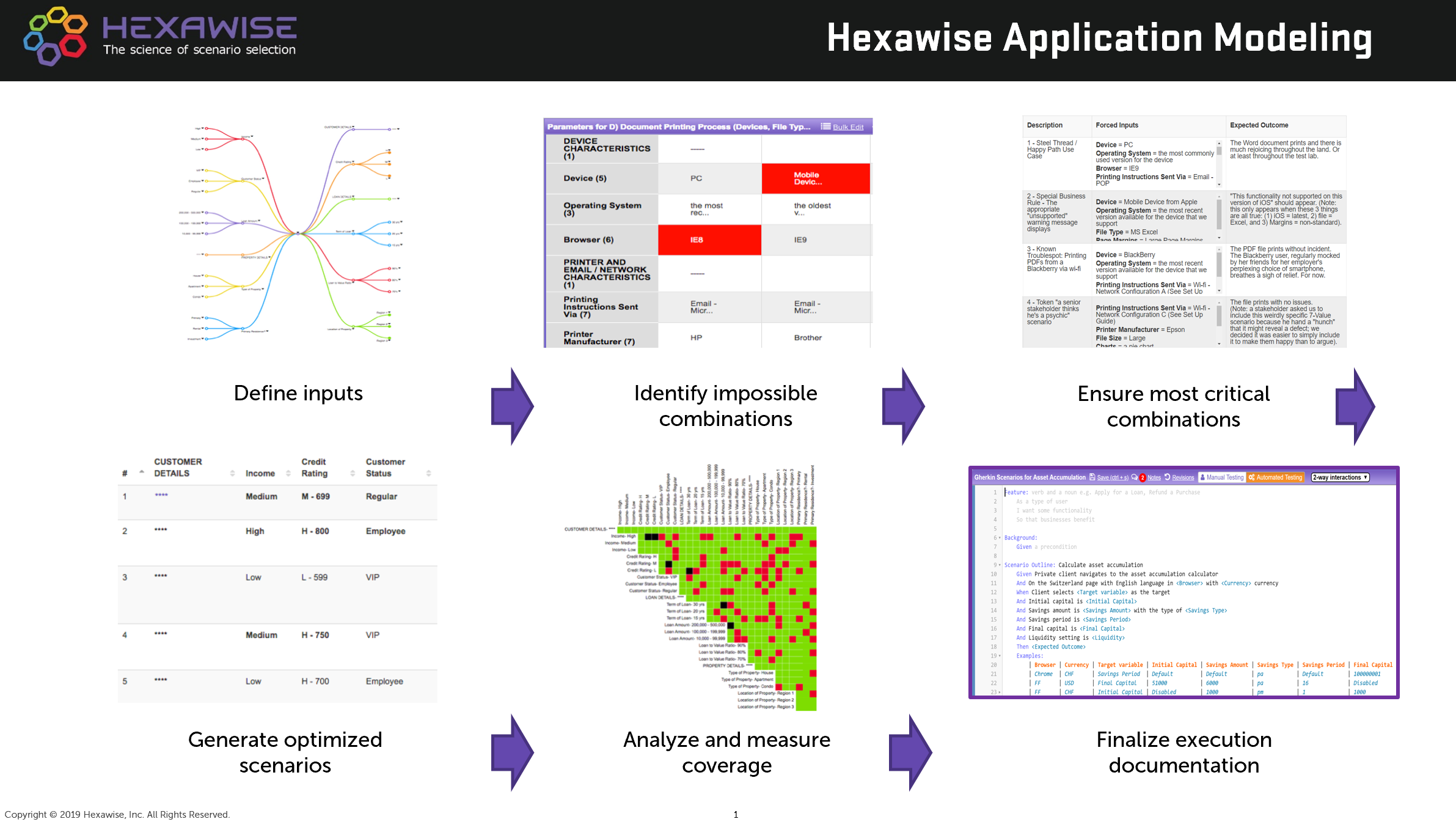
It can be aggregated into four key stages.
Stage 1: Begin test design efforts focusing on potential variation in the system under test
Instead of focusing only on details specified in requirements documentation, it is crucial to take a step back and evaluate what matters for the system as a whole. It is necessary to analyze which steps a user could take in an application and which choices they could have at each step. Then it is important to think about external elements that could affect user behavior (dependencies with other applications, environments, etc.). Finally, testers should organize that information in the appropriate form, like parameter/value tables, in order to review this information with stakeholders. Hexawise mind maps (first image on the top diagram above) can also be useful to facilitate such discussions.
Once all the key input parts of the model have been agreed upon, the team should proceed to the analysis of the constraints (i.e. how inputs can and can’t interact with each other) and requirements (both formal and informal).

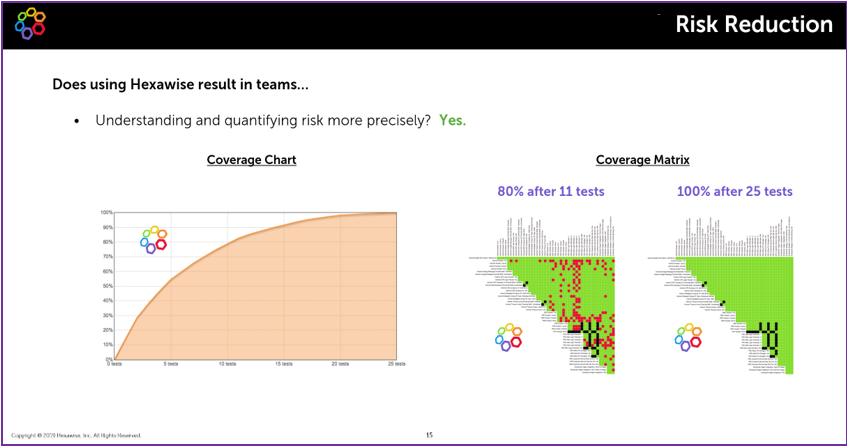
Further, it’s crucial to understand the level of interaction coverage of the test suite as on average 84% of defects in production are caused by 1 or 2 system elements acting together in a certain way. Evaluating the test suite at the model level leads to risk reduction through a clear understanding of what exactly is covered in each set of tests (for example, by leveraging the coverage graph & matrix in Hexawise).
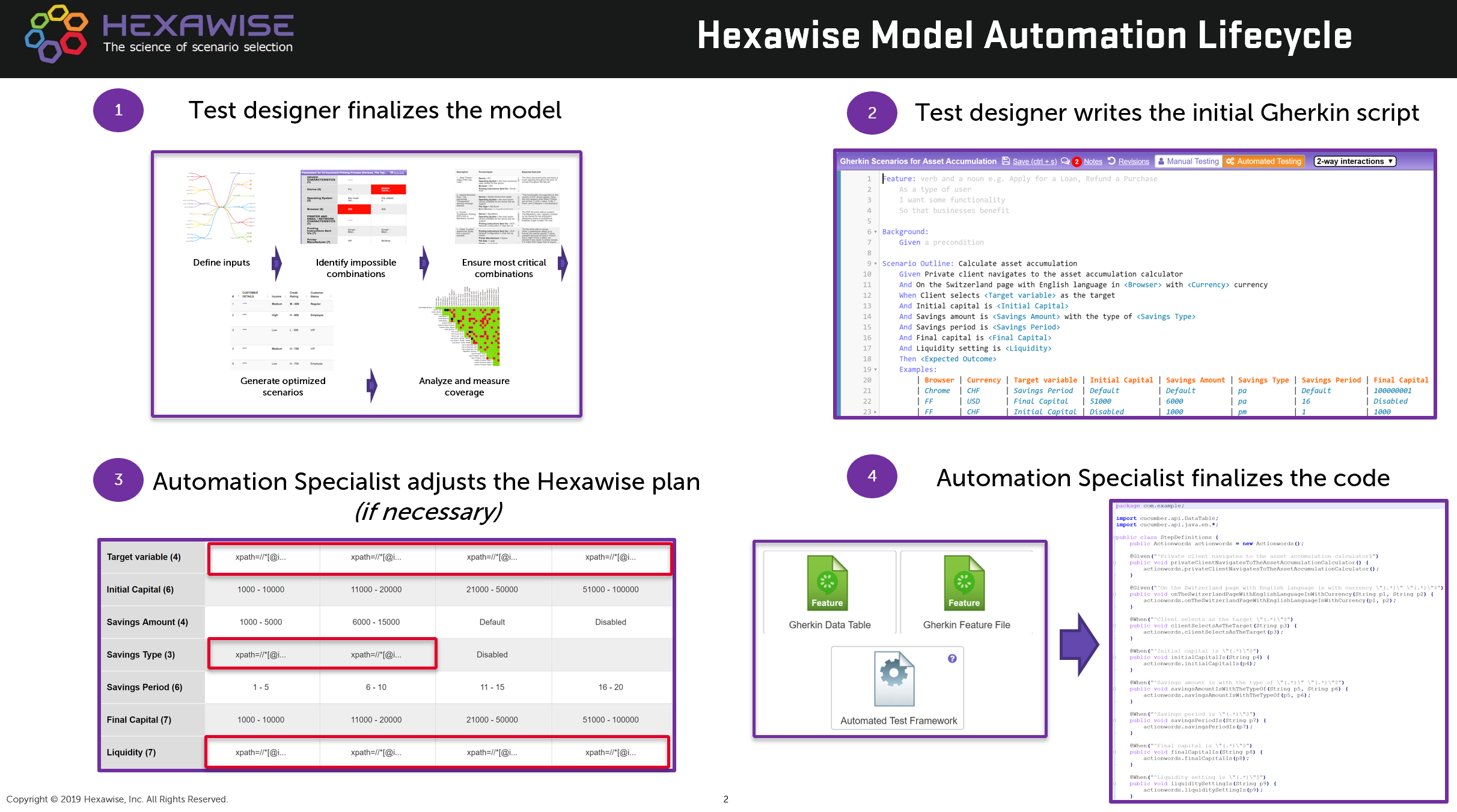
Stage 3: Create consistent and accurate documentation
Increasing the consistency and reducing the ambiguity of both script steps and expected results improves execution time & effort and makes automation more straightforward. When considering the expected results, it is important to precisely identify which combination of inputs trigger each desired outcome.
Hexawise allows you to create a single script for the model that is automatically applied to each of your test scenarios. This allows for creating data-driven test scripts and ensures the script creation effort does not increase linearly with each test scenario. The tool also allows users to incorporate the appropriate logic for expected result generation.
Stage 4: Simplify test case maintenance over time
One of the key advantages of data-driven testing is the ability to make a single update to the model’s inputs and have that update automatically applied to all of the test scenarios. This saves significant time and effort maintaining a test suite over time and helps ensure consistency and accuracy of all test cases. Hexawise also allows you to export the updated artifacts in a variety of formats for use with test case management and test automation tools.
Related: Create a Risk-based Testing Plan With Extra Coverage on Higher Priority Areas - Using Hexawise to Reduce Test Cases by 95% While Increasing Test Coverage - Manage regression tests at the "model level" to save time and avoid ever-increasing numbers of tests - How Not to Design Pairwise Software Tests


